A*寻路算法
A*寻路算是游戏开发中很常见的一种寻路算法,网络上相关的介绍也非常多,这次从其他寻路算法谈起,来看一看A星算法是如何诞生的,本文所有寻路算法使用TypeScript实现
算法默认权重不为负数
广度优先搜索
广度优先搜索,就如同洪水一样,从搜索起点不断往外扩张

搜索实现
- 构建一个搜索队列searchList,列表中的节点就是等待搜索的节点,初始化时将起点加入到列表中; 构建一个searchRecord记录被搜索过的节点
- 从searchList搜索队列中取出一个节点,获取到该节点的临近节点(这里取上下左右4个节点),若临近节点没有被搜索过,将临近节点加入到searchList中
- 重复步骤2,直到搜索完所有节点
提前结束
上面的搜索步骤是地图中所有节点进行遍历,实际上寻路都存在一个或多个目标,当搜索到目标就可以停止算法,避免不必要的查询
关于searchRecord
serachRecord用来记录搜索过的节点,当寻找到最终目标,最终的搜索路径就通过serachRecord构建出来, 我这里使用的是一个Dictionay来实现的,key是由节点的xy值构成的一个字符串,以表示一个唯一的节点,
比如,当我们以(5,5)为起点,[(4, 5), (5, 4), (5, 6), (6, 5)]这四个点将会被搜索,那么searchReocrd的结构就是这样的1
2
3
4
5
6searchRecord = {
'4_5': Node(5, 5),
'5_4': Node(5, 5),
'5_6': Node(5, 5),
'6_5': Node(5, 5)
}
这样的结构表明了key与value的父子关系: (5, 5) -> (4, 5), 当搜索继续下去,可能会出现下面的结果1
2
3
4
5
6
7searchRecord = {
'4_5': Node(5, 5),
'3_5': Node(4, 5),
'2_5': Node(3, 5),
'1_5': Node(2, 5),
......
}
假如(1, 5)是我们的终点,那么根据searchRecord我们可以轻松构建出最终的搜索路径: (5, 5) -> (4, 5) -> (3, 5) -> (2, 5) -> (1, 5)
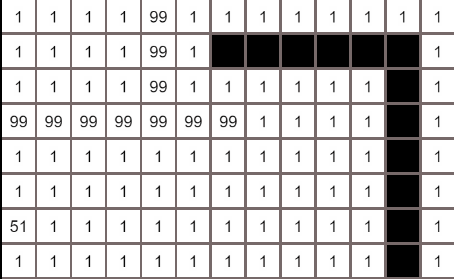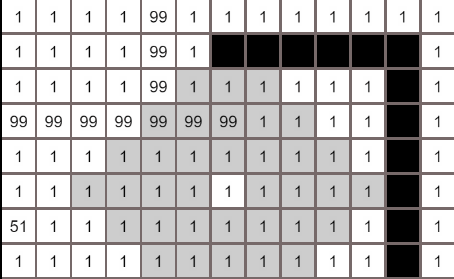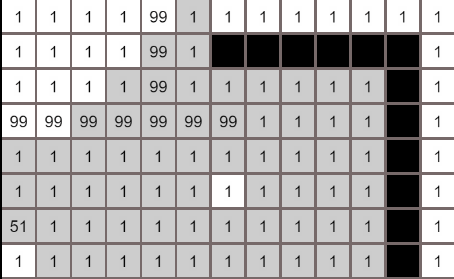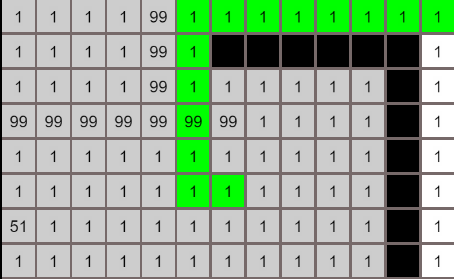
核心代码实现
1 | let searchQueue: Array<Node> = [start]; |
Dijkstra搜索
通常在游戏中,角色在不同的环境,机动能力是不同的,角色通过一格平原可能花费1点行动力,通过山地就要花费3点,还有河流,冰川….. 在广度优先搜索中,searchList中的节点没有权重的概念,而Dijkstra算法在广度优先搜索的基础上加入了权重,权重高(游戏中可能表现为移动损耗低)的节点会优先进行搜索, 以寻找移动损耗更低的路径
搜索节点加权
Dijkstra搜索中,每个节点都有一个权重值,代表着移动所需要的消耗,广度优先搜索其实也是特殊的Dijkstra搜索,所有的节点权重都是1
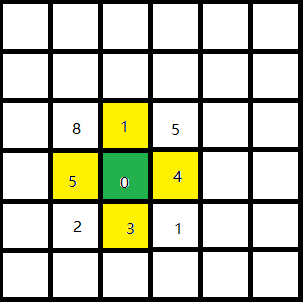
在上图中,以绿色点为起点进行搜索,首先将4个黄色的邻居节点加入到搜索列表中,他们以降序权重(值越小权重越高)在列表中排列:[1, 3, 4, 5],下一轮搜索将取“1”节点进行搜索,重复上述的步骤,直到搜索结束
在算法中,新加入了一个Dictionary costRecord用来记录从起点到每一个节点的消耗,每个节点的消耗=父节点的消耗+节点的权重值; 如果节点已经搜索过,就不再搜索
优先级队列
这里不能简单的使用广度优先搜索的list,在加入新的节点到searchList中时,我们需要对节点进行排序,搜索的时候直接从队头或队尾(取决于排序的升降序)取出节点进行搜索
如何保证最后的路径就是cost最低的路径?
因为在搜索循环中,始终是先搜索cost最低的节点,最先抵达终点的路径必定是cost最低的路径
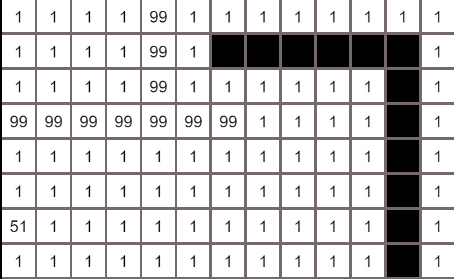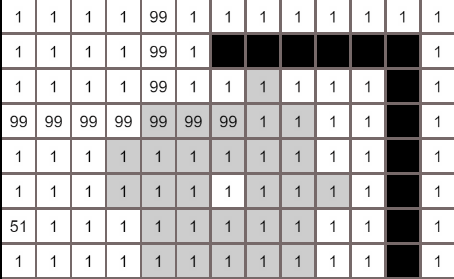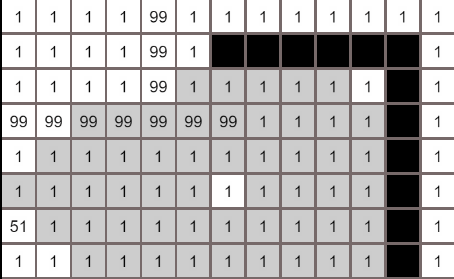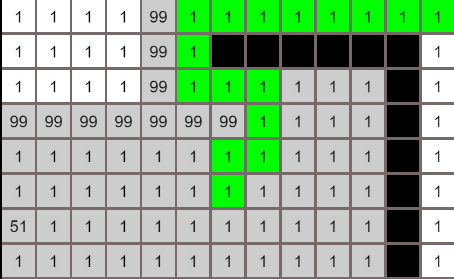
上图中,箭头指向的节点表示是箭头所在的节点是被箭头指向的节点搜索到的,搜索的范围像洪水一样往外扩展,左上角由于被过高cost的节点阻挡,终止了搜索,searchRecord记录了所有搜索路径,因为是先搜索最低cost的节点,所以最先抵达终点的路径就是最低cost路径(试想一下,算法以最低代价进行搜索找到的节点,还会有另一条代价更低的路径到这个节点吗)
核心代码实现
1 | let searchQueue: PriorityQueue = new PriorityQueue(); |
最佳优先搜索
上面提到的两种算法,都是在不断的搜索地图里面的节点,当“碰巧”遇到了目标节点,才结束查询,期间有太多无意义的搜索; 而我们寻路是知道目标的方位的,查找的时候直接朝这个放下搜索不久可以省去多余的搜索了么,最佳优先搜索就是这么干的
以离目标的距离为优先级
该算法计算每一个节点到终点的距离,优先搜索距离目标最近的节点,这样搜索就是朝着目标不断前进的
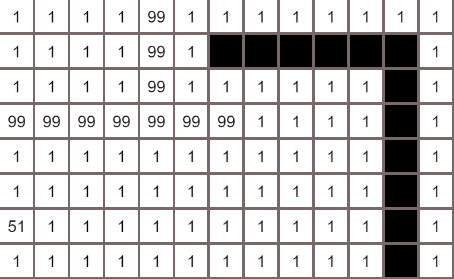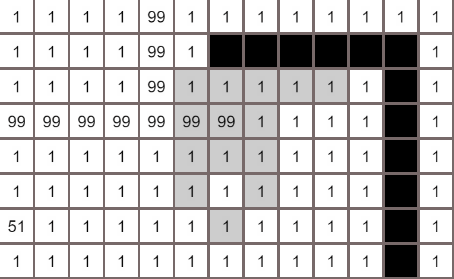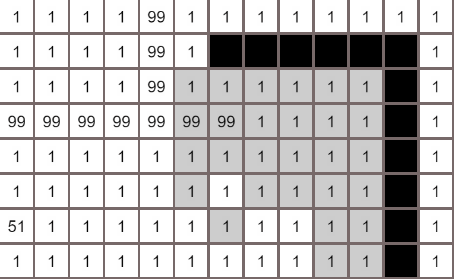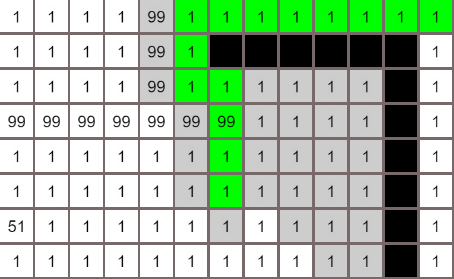
何如结算节点与目标的距离
在我们的例子中,只有上下左右四个移动方向,使用曼哈顿距离最为合适,所谓曼哈顿距离,就是两个节点的x轴与y轴的距离之和1
2
3heuristics(start: Node, end: Node){
return Math.abs(start.x - end.x) + Math.abs(start.y - end.y);
}
核心代码实现
1 | let searchQueue: PriorityQueue = new PriorityQueue(); |
最佳优先搜索的结果可能不是最短路径
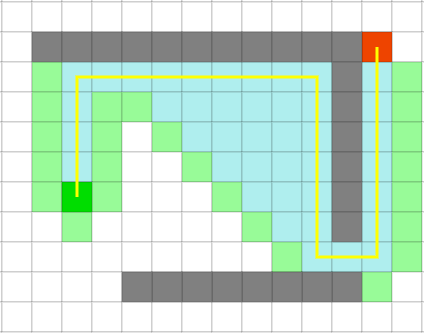
在多个结点cost相同的情况下,上图是优先往上搜索,然而最佳优先搜索只是贪婪的朝目标前进,最后被障碍物挡住,只得向下绕行,所以本算法在存在障碍物的情况下(多数寻路都存在障碍物),不能够保证是最短路径,想要高效的找到最短路径,就需要试试集各家之所长的A*算法了
A*搜索
A*融合了最佳优先搜索和Dijkstra搜索的优点,同时使用节点移动权重和节点离终点的距离,对节点的搜索优先级进行评估
有如下公式:
F(x) = G(x) + H(x)
- F(x)为x节点的搜索权重,权重越小越先被搜索
- G(x)为从起点移动到x节点的cost
- H(x)为从x节点到终点的距离
核心代码实现
我们只需要对最佳搜索算法稍加改造1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23let searchQueue: PriorityQueue = new PriorityQueue();
let searchRecord = {};
let costRecord = {};
searchRecord[start.toString()] = true;
costRecord[start.toString()] = 0;
searchQueue.put(start, this.heuristics(start, end) + costRecord[start.toString()]);
while(searchQueue.length){
let current = searchQueue.get();
if(current.getNode().toString() == end.toString()){
break;
}
let neighbors = this.getNeighbors(current.getNode());
for(let node of neighbors){
let newCost = node.cost + costRecord[current.getNode().toString()];
if(costRecord[node.toString()] === undefined){
costRecord[node.toString()] = newCost;
searchRecord[node.toString()] = current.getNode();
//节点的搜索优先级将由cost和离终点距离决定
searchQueue.put(node, newCost + this.heuristics(node, end));
}
}
}
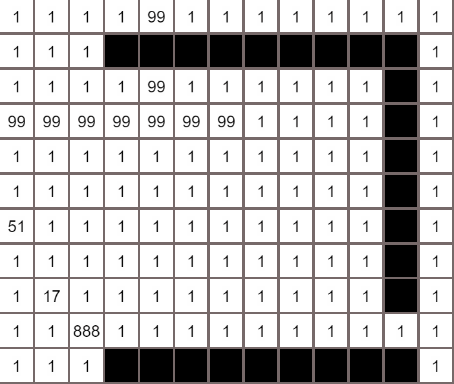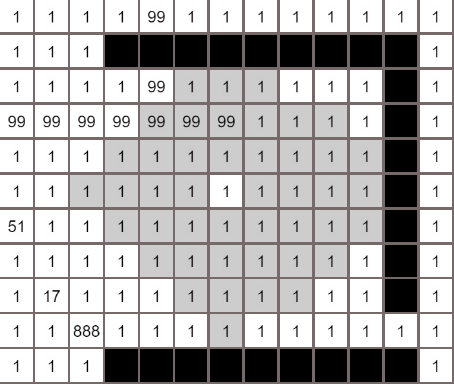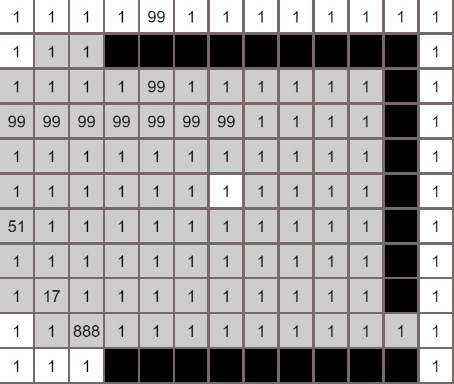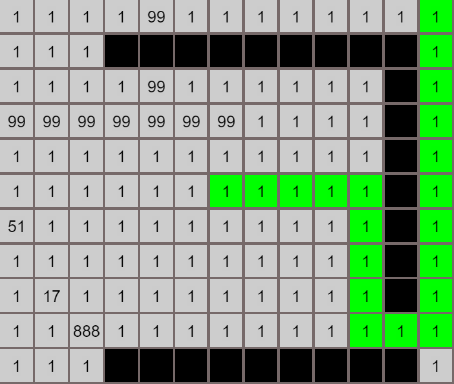
各个算法的对比
A*算法
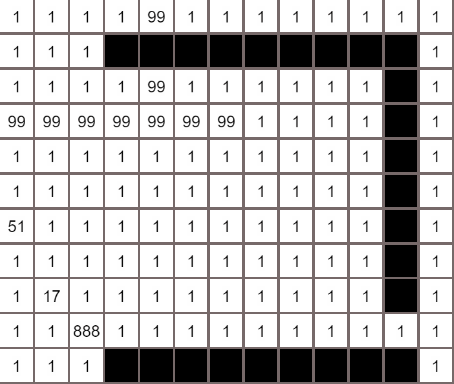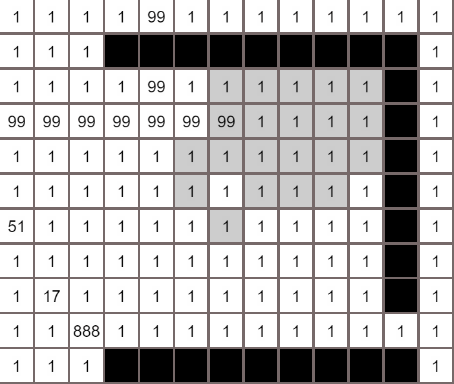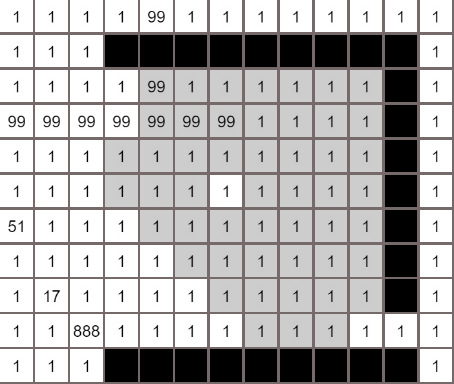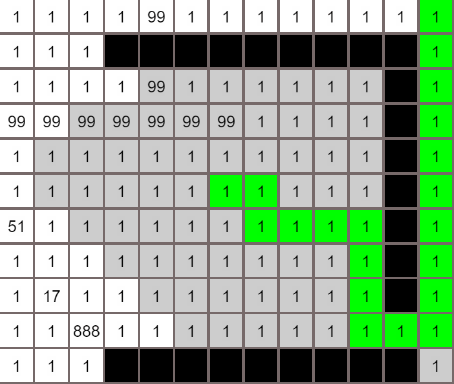
最佳优先算法
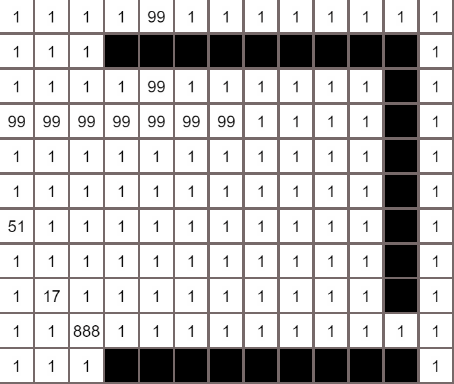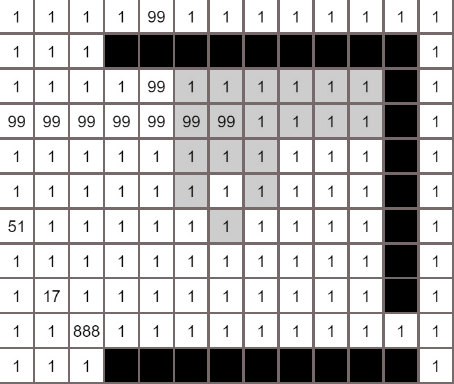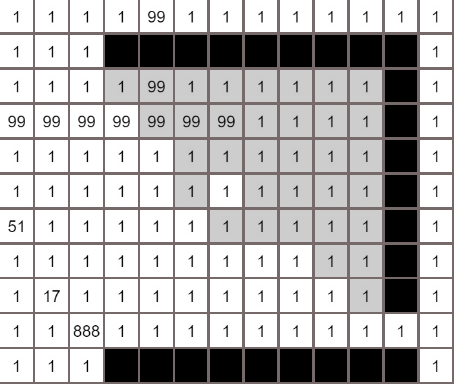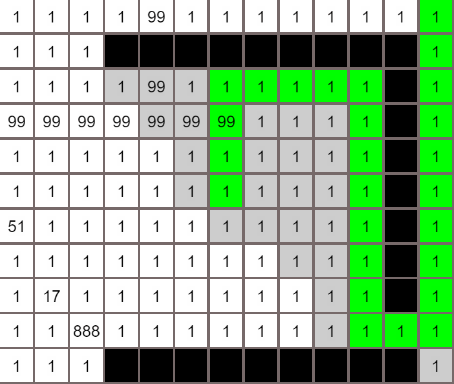
Dijkstra算法
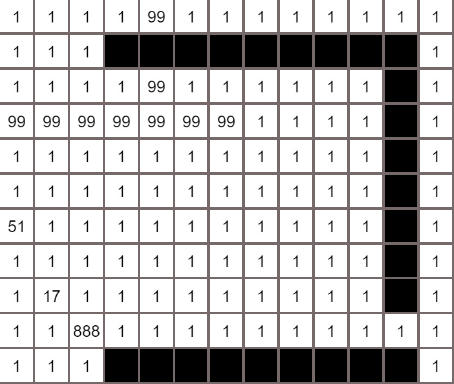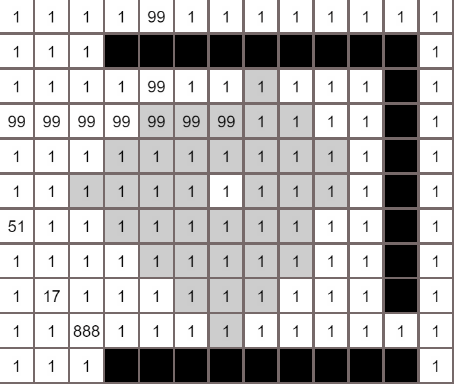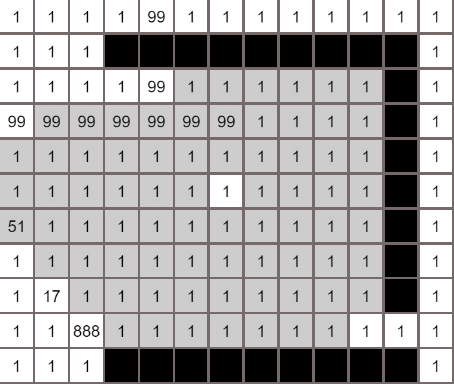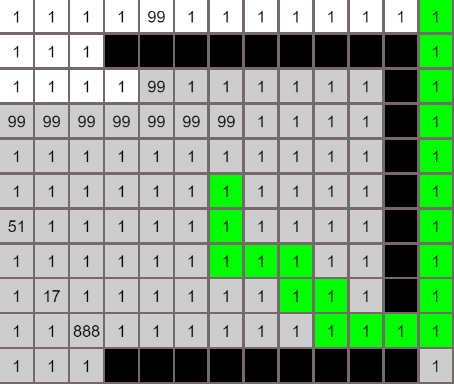
广度优先算法
最后
本文只是简单讲述了一下AStar是怎样演变而来的,使用的Astar算法也是非常原始,现在Astar算法也在不断的变化,出现了很多优化版本,有兴趣深入研究的可以直接在网络上查询
寻路测试demo源码地址:https://github.com/cdjinwei/SearchPath
参考文章:https://www.redblobgames.com/pathfinding/a-star/introduction.html